
环境:
- centos7.6
- spark运行有3中模式,这里选择spark on yarn
一、 安装jdk
[root@cmf-test-spark-client tmp]# yum install java-1.8.0-openjdk -y
二、spark安装
[root@cmf-test-spark-client tmp]# mkdir /usr/local/spark -p
[root@cmf-test-spark-client tmp]# tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /usr/local/spark/
[root@cmf-test-spark-client tmp]# cd /usr/local/spark/
三、配置环境变量
[root@cmf-test-spark-client tmp]# vi /etc/profile
添加
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64/jre
export SPARK_HOME=/usr/local/spark/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPAHT=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
[root@cmf-test-spark-client tmp]# source /etc/profile
四、配置spark
[root@cmf-test-spark-client tmp]# cd /usr/local/spark/
[root@cmf-test-spark-client ~]# cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7/conf/
[root@cmf-test-spark-client conf]# cp spark-env.sh.template spark-env.sh
[opadm@xiangys0134-haddop03 conf]$ vi spark-env.sh
添加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
#export SCALA_HOME=/home/software/scala2.11
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
export YARN_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
export SPARK_HOME=/usr/local/spark/spark-2.3.0-bin-hadoop2.7
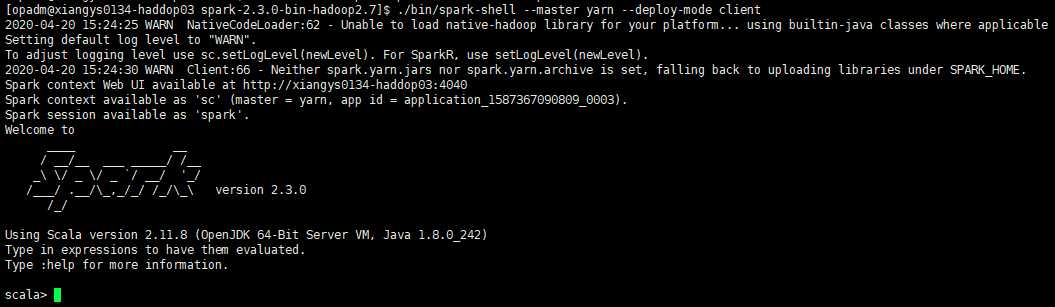
五、验证在yarn运行
[opadm@xiangys0134-haddop03 spark-2.3.0-bin-hadoop2.7]$ ./bin/spark-shell --master yarn --deploy-mode client
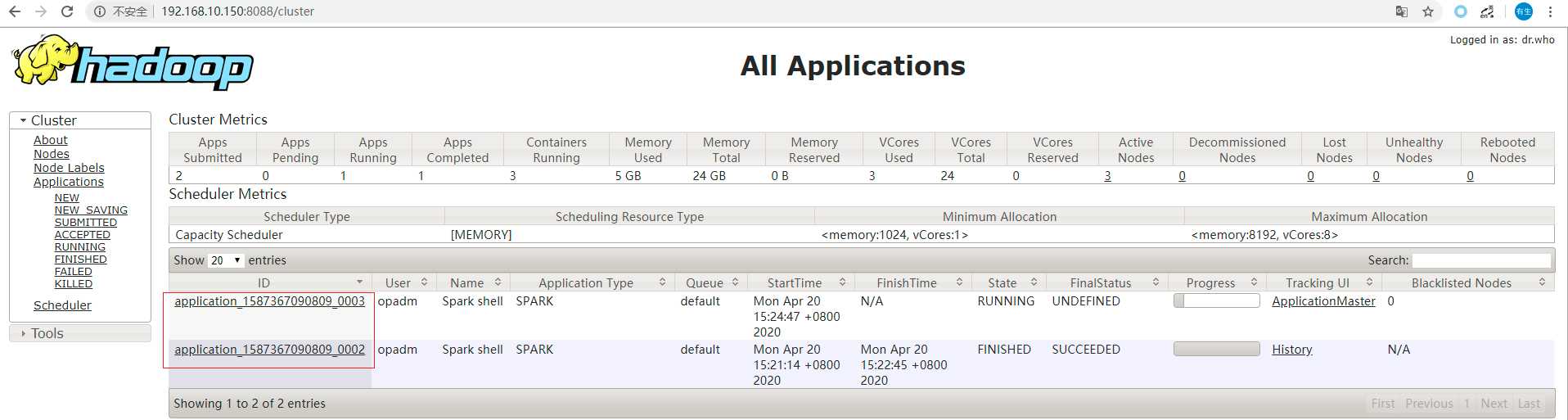
六、通过yarn查看任务
留言